library(tidyverse)
library(summarytools)
GTDSpart <- GTDSroh %>% dplyr::select(DIAALTER,DIAALTERkorr)
summarytools::descr(GTDSpart, stats = "common")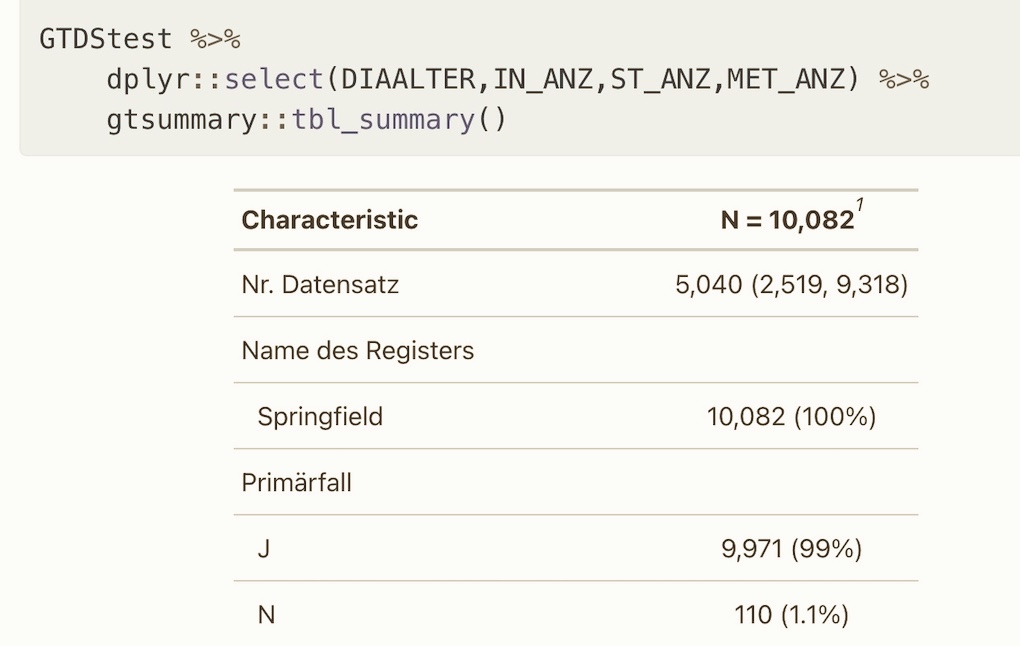
Die Datenverteilung - Lagemaße
Wir haben zuvor gesehen, dass bereits mit einfachen Mitteln umfangreiche Fragestellungen in R erarbeitet werden können. Im Blogbeitrag “Deskriptive Statistik” haben wir die Verteilung der Variable DIAALTER und ihrer Korrektur-Verwandten DIAALTERkorr untersucht.
Zur Erinnerung:
Das Ergebnis war so überzeugend, dass wir im folgenden die Korrekturfunktion für DIAALTER gleich auf DIAALTER selbst angewendet haben.
Wir gehen mit einigen wichtigen Variablen aus dem exportierten Datensatz etwas weiter in die Tiefe. Uns geht es nicht nur um zuverlässige statistische Funktionen, sondern auch um eine repräsentative Darstellung der Ausgabe.
Damit sich die Anwendung lohnt, wollen wir weitere Variablen heranziehen. Neben dem Diagnosealter ist die Überlebenszeit in der Onkologie sehr wichtig. Diese gibt es als Gesamtüberleben (Diagnosedatum bis zur letzten Kontrolle, oder bis zur letzten Nachricht, oder bis zum Todeszeitpunkt) und als rezidivfreies Überleben (Diagnosedatum bis zum ersten Erkrankungsrückfall). GTDS hat unserer Datentabelle neben dem Alter bei Diagnose (Variable DIA_DAT) noch weitere Daten mitgegeben. Das Datum des Rückfalls ist als Variable REZ1_DAT vorhanden, das Datum des letzten Kontakts als LINF_DAT, und falls zutreffend das Sterbedatum STERBDAT. Diese Daten liegen in der importierten Rohdaten-Tabelle (aufgrund der Import-Methode) sämtlich als Zeichenwerte in einem standardisierten Format vor, und sind deshalb universell verwendbar. Sie müssen jedoch in Datumswerte (Zahlenwerte im Datumsformat) gewandelt werden, um mit ihnen rechnen zu können.
Die Datumsfunktionen entnehmen wir dem bereits besprochenen Paket “lubridate”, das viele mögliche Probleme im Umgang mit Datumswerten (z.B. Schaltjahr oder Zeitzonen) berücksichtigt und ebenfalls dem Tidyverse angehört. Das Paket wird durch Laden des Tidyverse gleich mitgeladen. Nebenbei: Die gezeigte Konversionslösung könnte sicherlich vereinfacht werden - hier geht es eher darum, das Beispiel nachvollziehbar zu gestalten.
library(tidyverse)
GTDStest <- GTDSroh %>% dplyr::mutate(lubridate::parse_date_time(DIA_DAT, "dmy"))
GTDStest %<>% dplyr::mutate(lubridate::parse_date_time(LINF_DAT, "dmy"))
GTDStest %<>% dplyr::mutate(lubridate::parse_date_time(REZ1_DAT, "dmy"))
GTDStest %<>% dplyr::mutate(lubridate::parse_date_time(STERBDAT, "dmy"))
GTDStest %<>% dplyr::mutate( DIAALTER = (GEB_DAT %--% DIA_DAT) / years(1))
GTDStest %<>% dplyr::mutate(OS = (DIA_DAT %--% LINF_DAT) / years(1))
GTDStest %<>% dplyr::mutate(RezDat = (DIA_DAT %--% REZ1_DAT) / years(1))
GTDStest %<>% dplyr::mutate(OS = (SterbeDatum %--% STERBDAT:DAT) / years(1))Für unsere Ziele (verlässliche Statistik, aber auch ansprechende Ausgabe der Ergebnisse) verwenden wir in den folgenden Abschnitten Funktionen zur Tabellendarstellung. In R sind eine Vielzahl von Optionen verfügbar, Tabellen zu erzeugen. Einige dieser Funktionspakete bieten eine besonders präsentable Ausgabe, die bis zur “Druckreife” reicht.
Die ansprechende tabellarische Darstellung von Statistiken ist ein eigenes Thema, vor allem wenn es um die Auswahl des jweils (vermeintlich) besten Funktionspaketes geht. An dieser Stelle ist ein solcher tiefer gehender Vergleich nicht intendiert. Erst irgendwann später sollen die jeweiligen Vor- und Nachteile einzelner Funktionspakete angeschaut werden.
Hier wollen wir uns vorausgewählten Funktionspaketen bedienen, die aus unserer Sicht eine ansprechende Tabellenausgabe bieten, und sich gleichzeitig in die Tidyverse-Umgebung einfügen. Zum Vergleich wird “summarytools” verwendet, zum anderen “gtsummary” als Ergänzung zum Funktionspaket “gt” (“grammar of tables”) ).
Aus dem Paket “gtsummary” nehmen wir die Funktion “tbl_summary()”. Diese Funktion bietet neben den üblichen, konfigurierbaren statistischen Parametern kontinuierlicher numerischer Variablen auch die Analyse dichotomer oder kategorialer Variablen - sogar in der Voreinstellung und ohne Zutun. Die Druckausgabe ist bemerkenswert gut, und dies in der Voreinstellung.
Zum Vergleich wurde die Ausgabe mit “summarytools” dargestellt.
Beachte nebenbei, wie der Pipe-Operator “%>%” die Lesbarkeit der Datenstruktur deutlich verbessert, und die schrittweise Datenweitergabe verdeutlicht.1
library(tidyverse)
library(summarytools)
library(gtsummary)
GTDStest <- GTDSroh %>%
dplyr::select(AUSW_DAT,SATZ_NR,REGISTER,PRIMFALL,PAT_ID,TUMOR_ID,DIAALTER,SEX,DIAICD10,OP_ANZ,IN_ANZ,ST_ANZ,MET_ANZ,OS)
GTDStest %>%
dplyr::select(DIAALTER,SEX,OS) %>%
summarytools::descr(stats = "all", style = "rmarkdown", display.labels = TRUE)
GTDStest %>%
dplyr::select(DIAALTER,SEX,OS) %>%
gtsummary::tbl_summary()Zunächst eine Tabellenausgabe mit “summarytools”. Die kategoriale Variable “SEX” wird von der Darstellung ausgeschlossen:
Non-numerical variable(s) ignored: SEXDescriptive Statistics
GTDStest
N: 10082
| DIAALTER | OS | |
|---|---|---|
| Mean | 65.31 | 3.34 |
| Std.Dev | 35.40 | 27.85 |
| Min | -1747.76 | -0.48 |
| Q1 | 57.41 | 0.34 |
| Median | 67.24 | 1.56 |
| Q3 | 75.59 | 3.96 |
| Max | 103.10 | 1813.48 |
| MAD | 13.25 | 2.12 |
| IQR | 18.18 | 3.62 |
| CV | 0.54 | 8.34 |
| Skewness | -42.48 | 59.94 |
| SE.Skewness | 0.02 | 0.02 |
| Kurtosis | 2113.48 | 3755.12 |
| N.Valid | 9931.00 | 9932.00 |
| Pct.Valid | 98.50 | 98.51 |
Und jetzt eine Darstellung mit “gtsummary”. Beachte den geänderten Tabellenaufbau, der sich entsprechend der unterschiedlichen Aufgabenstellung ergibt. Die Variable “SEX” wird mit wichtigen statistischen Kennzahlen aufgeführt:
| Characteristic | N = 10,0821 |
|---|---|
| DIAALTER | 67 (57, 76) |
| Unknown | 151 |
| SEX | |
| M | 3,515 (35%) |
| W | 6,552 (65%) |
| Unknown | 15 |
| OS | 1.6 (0.3, 4.0) |
| Unknown | 150 |
| 1 Median (Q1, Q3); n (%) | |
Footnotes
Inzwischen verfügt auch die Basissprache R seit Release 4.1.0 über einen (nun nativen) Pipe-Operator: ” |> “. Dieser ist in der Funktionalität aber nicht glechzusetzen mit dem (nachzuladenden)”magrittr” Operator ” %>% “. Die Unterschiede können im Einzelfall relevant sein, würden aber den Zusammenhang an dieser Stelle sprengen. Der native Pipe-Operator kann allerdings ohne die Abhängigkeit zu einem Erweiterungspaket verwendet werden (was wir in unserem Fall aber aus anderen Gründen benötigen).↩︎